
多言語のAI音声読み上げの課題と調整方法 ー後編ー
アクセシブルコード
アクセシブルコードは、日本語を読めない外国の方や視覚障害者の方に向けて開発された、音声情報を提供する2次元コードです。この2次元コードは、一つのコードで複数の言語のコンテンツを表示でき、音声合成ソフトウェアを利用して各言語で音声を提供しています。
前編では、日本語、英語、中国語及び韓国語によくある音声調整の方法を紹介しました。音声読み上げの問題は基本的にネイティブの方にチェックしていただければ気づくものですが、ネイティブの方にとってもチェックや調整が難しい言語があります。後編ではベトナム語、タイ語及びアラビア語を例にしてご紹介いたします。
ベトナム語
ベトナム語は声調記号が付いているアルファベット表記言語です。ベトナム語にない単語の場合は、英語をそのまま使用することが可能です。

1. 書き方と読み方の違い
英語とベトナム語が混在すると、AI読み上げソフトが正しく区別できないため、英語表記を正しいベトナム語の読み方に調整する必要があります。
| 書き方 | 読み方 |
|---|---|
| IT | ai-ti |
| SNS | ét-en-ét |
| SDGs | ét-đi-gi |
2. 略称の問題
AI読み上げソフトは略称の認識ができません。例えばベトナム語「vân vân(など)」の略語は「v.v.」と表記されますが、「vân vân」と読ませたいので、表記と読み方を異なるように調整することが必要です。
3. 数字の問題
ベトナム語の教科書では「1,000」は「1.000」と書きます。3桁ごとの区切りに「,」カンマではなく、「.」ピリオドを付けます。数字がある場合、どう読み上げられるか、文脈に基づいてネイティブの方に判断してもらう必要があります。
タイ語
1. スペリングの問題
AI読み上げソフトでは、単語では正しく読み上げられたとしても、文章中では変な発音になる場合があります。「私たち」という意味の「เรา」(ラウー)は、文章の前後の影響を受けて、「เร อา」(レ・ア)のように読み上げられてしまう場合があります。そのようなときは、「เรา」を1つの単語としてAI読み上げソフトが認識できるように調整をします。
2. 表記の問題
いきなりですがクイズです。この2つのタイ語の単語は、どこが違うでしょうか?

通常のタイ語文字よりかなり拡大して見やすくしても、なかなか違いが分からないかと思います。
タイ語の文字は44子音字があります。それぞれの子音字は似ている部分がありますので、念入りに気を付けて表記&音声を確認しないと、通常サイズのフォントではかなりミスしやすいです。クイズの答えは、以下の赤丸の部分。小さい〇があるかないかの違いだけで、意味が大きく異なります。

アラビア語
アラビア語がわからない人にとって謎のような神秘の文字と言っても過言ではないくらい最も調整が難しい言語の一つです。アラビア語では文章は右から左へ、数字は左から右へ表記します。日本で使われているテキストエディターはほとんど対応しておらず、アラビア語を正しく表記するため、ネイティブの方でも苦労しています。
1.スペースについて
アラビア語では、スペースにも方向があるため、ソースコードを作成する時に、簡単にコピー&ペーストすることができません。文章内に日付などの数字が入っている場合、読み上げる順序を調整する必要がありますが、スペースの関係で、意図しない場所に数字が入ってしまったりします。そのような場合は、ネイティブの方に音声を確認していただきながら修正対応します。
2.数字について
例えば、「0120-123-456」という電話番号の場合、表記は、日本語と同じで「0120-123-456」と書きますが、これをアラビア語の音声としてAI読み上げソフトが読み上げる場合、「654‐321‐0210」 のように逆から読んでしまいます。このような場合は、手動で修正をする必要があります。
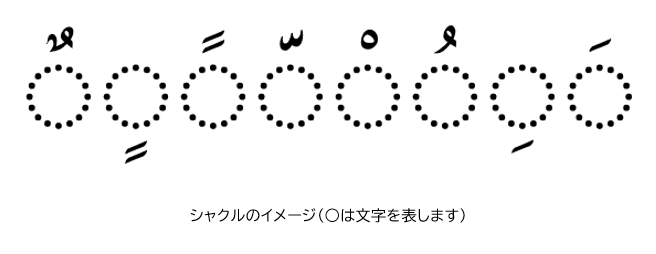
3. 発音記号について
アラビア語では「シャクル」という発音記号があります。人間はシャクルがなくても問題なく文章を読めますが、AI読み上げソフトはシャクルがないと発音が正しくできなかったり、シャクルがあっても発音がおかしい場合があります。普段はあまり使わないのですが、フリガナに似たものをhtmlに書き入れるなどの工夫を施すことで、AI読み上げソフトが認識できるようにします。
まとめ
このように、言語ごとに特性は大きく違うので多言語で情報を正しく読み上げられるようにするには、ネイティブによる対応が不可欠です。今後も異なる言語や文化に対応するための努力を続けることで、より良い情報社会の実現に貢献したいと思います。
※本記事内で挙げた例は、AI音声合成ソフトの一つである Readspeaker を使用した例です。